Linux正则表达式
正则表达式:Regual Expression, REGEXP
正则表达式的意义
处理大量的字符串
处理文本
通过特殊符号的辅助,可以让linux管理员快速过滤、替换、处理所需要的字符串、文本,让工作高效。
通常Linux运维工作,都是面临大量带有字符串的内容,如:
正则表达式是一套规则和方法
Linux三剑客
文本处理工具,均支持正则表达式引擎
grep:文本过滤工具,(模式:pattern)工具,擅长单纯的查找或匹配文本内容 更适合编辑、处理匹配到的文本内容 更适合格式化文本内容,对文本进行复杂处理
基本正则表达式BRE集合
符号
作用
^尖角号,用于模式的最左侧,如 “^li”,匹配以li单词开头的行
$美元符,用于模式的最右侧,如"li$",表示以li单词结尾的行
^$组合符,表示空行
.匹配任意一个且只有一个字符,不能匹配空行
\转义字符,让特殊含义的字符,现出原形,还原本意,例如.代表小数点
*匹配前一个字符(连续出现)0次或1次以上 ,重复0次代表空,即匹配所有内容
.*组合符,匹配任意长度的任意字符
^.*组合符,匹配任意多个字符开头的内容
.*$组合符,匹配以任意多个字符结尾的内容
[abc]匹配[]集合内的任意一个字符,a或b或c,可以写[a-c]
[^abc]匹配除了^后面的任意字符,a或b或c,^表示对[abc]的取反
<pattern>匹配完整的内容
<或>定位单词的左侧,和右侧,如可以找出"a b c",找不出"d"
扩展正则表达式ERE集合
字符
作用
+匹配前一个字符1次或多次,前面字符至少出现1次
[:/]+匹配括号内的":“或者”/"字符1次或多次
?匹配前一个字符0次或1次,前面字符可有可无
|表示或者,同时过滤多个字符串
()分组过滤,被括起来的内容表示一个整体
a{n,m}匹配前一个字符最少n次,最多m次
a{n,}匹配前一个字符最少n次
a{n}匹配前一个字符正好n次
a{,m}匹配前一个字符最多m次
grep
全拼 :Global search REgular expression and Print out the line.作用 :文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查,打印匹配到的行模式 :由正则表达式的元字符及文本字符所编写出的过滤条件;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 语法: grep [options] [pattern] file 命令 参数 匹配模式 文件数据 -A<显示行数>:除了显示符合范本样式的那一列之外,并显示该行之后的内容。 -B<显示行数>:除了显示符合样式的那一行之外,并显示该行之前的内容。 -C<显示行数>:除了显示符合样式的那一行之外,并显示该行之前后的内容。 -c:统计匹配的行数 -e :实现多个选项间的逻辑or 关系 -E:扩展的正则表达式 -f FILE:从FILE获取PATTERN匹配 -F :相当于fgrep -i --ignore-case -n:显示匹配的行号 -o:仅显示匹配到的字符串 -q: 静默模式,不输出任何信息 -s:不显示错误信息。 -v:显示不被pattern 匹配到的行,相当于[^] 反向匹配 -w :匹配 整个单词
参数选项
解释说明
-v
排除匹配结果,相当于[^] 反向匹配
-n
显示匹配行与行号
-i
不区分大小写
-c
只统计匹配的行数
-E
使用egrep命令
–color=auto
为grep过滤结果添加颜色
-w
只匹配过滤的单词
-o
只输出匹配的内容
正则表达式grep实践
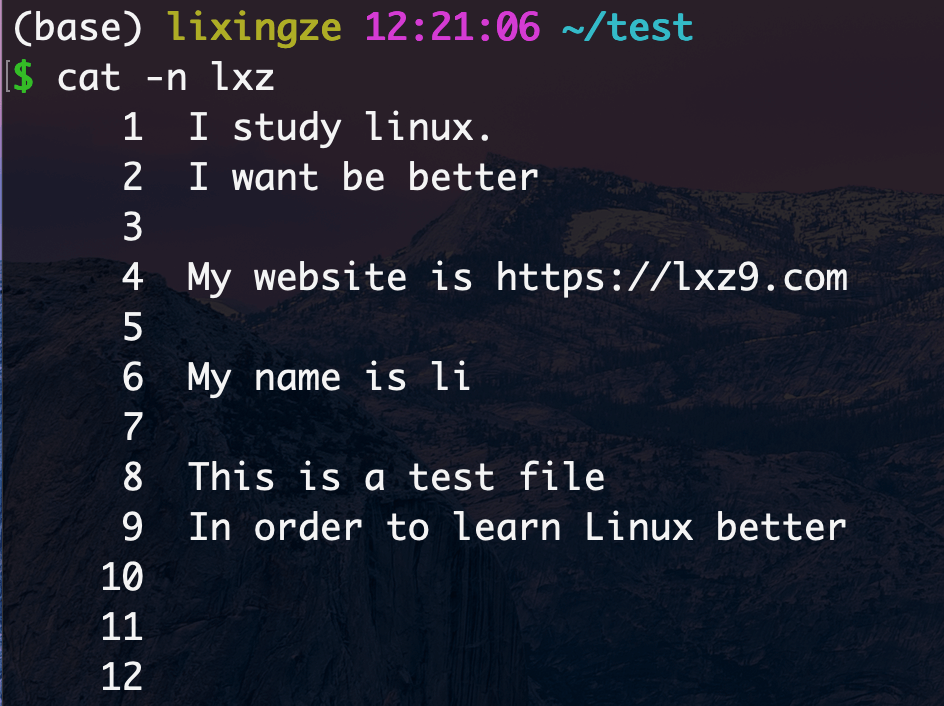
准备测试文件
^符号1 2 3 4 grep -i -n "^i" lxz # -i忽略大小写 -n 显示仪行号 1:I study linux. 2:I want be better 9:In order to learn Linux better
1 2 grep -i -n "^t" lxz 8:This is a test file
$符1 2 3 grep -i -n "r$" lxz 2:I want be better 9:In order to learn Linux better
1 2 grep -i -n "m$" lxz 4:My website is https://lxz9.com
1 2 3 4 5 6 7 8 9 10 11 12 1.注意不加转义符的结果,正则里"."是匹配任意1个字符,grep把.当做正则处理了,因此把有数据的行找出来了, $ grep -i -n ".$" lxz 1:I study linux. 2:I want be better 4:My website is https://lxz9.com 6:My name is li 8:This is a test file 9:In order to learn Linux better 2.加上转义符,当做普通的小数点过滤 $ grep -i -n "\.$" lxz 1:I study linux.
^$组合符1 2 3 4 5 6 7 $ grep "^$" -n lxz 3: 5: 7: 10: 11: 12:
.点符号.点表示任意一个字符,有且只有一个,不包含空行
1 2 3 4 5 6 7 $ grep -i -n "." lxz 1:I study linux. 2:I want be better 4:My website is https://lxz9.com 6:My name is li 8:This is a test file 9:In order to learn Linux better
匹配出 .li,找出任意一个三位字符,包含li
1 2 3 4 $ grep -i -n ".li" lxz 1:I study linux. 6:My name is li 9:In order to learn Linux better
\转义符找出文中所有的点"."
1 2 3 $ grep "\." lxz I study linux. My website is https://lxz9.com
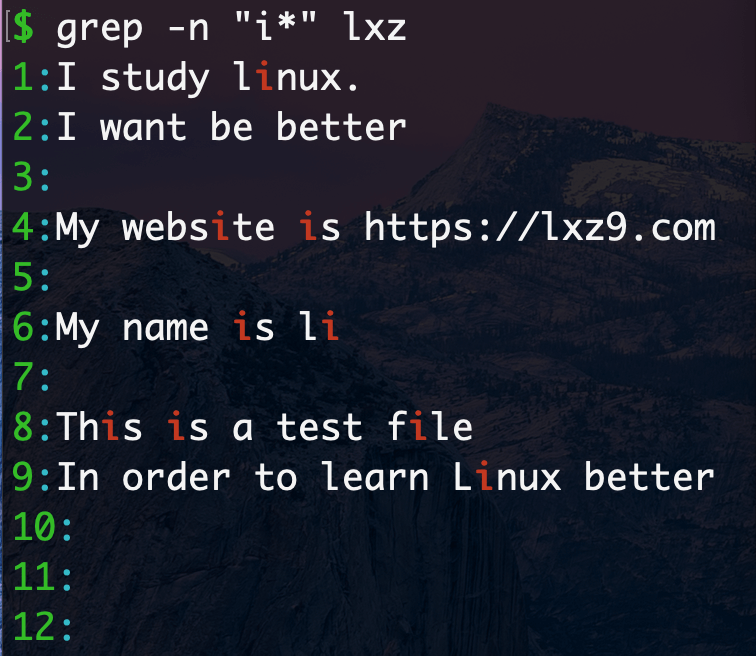
*符号找出前一个字符0次或多次,找出文中出现"i"的0次或多次
组合符
.表示任意一个字符,*表示匹配前一个字符0次或多次,因此放一起,代表匹配所有内容,以及空格
^以某字符为开头.任意0或多个字符.*代表匹配所有内容o普通字符,一直到字母o结束
[abc]中括号中括号表达式,[abc]表示匹配中括号中任意一个字符,a或b或c,常见形式如下
[^abc]中括号中取反[^abc]或[^a-c]这样的命令,^符号在中括号中第一位表示排除,就是排除字母a或b或c
grep参数 -o
使用"-o"选项,可以只显示被匹配到的关键字,而不是讲整行的内容都输出。
1 2 $ grep -o 'a' lxz | wc -l 4
扩展正则表达式实践
使用grep -E进行实践扩展正则
+号+号表示匹配前一个字符1次或多次,必须使用grep -E 扩展正则grep -E 'l+' lxz #匹配lxz文件中l字符一次或多次
?符匹配前一个字符0次或1次
找出文件中包含ab或aob的行
1 2 3 grep -E 'ao?b' luffycity.txt aob #字母o出现了一次 ab #字母o出现了0次
|符竖线在正则中是或者的意思
找出系统中的txt文件,且名字里包含a或b的字符
1 2 3 4 5 6 find /home/lixingze -maxdepth 3 -name "*.txt" |grep -i -E "a|b" /home/lixingze/.conda/environments.txt /home/lixingze/Database/data/go_tmp.txt /home/lixingze/Database/data/go_rich.significant.txt /home/lixingze/Database/go_R/go_tmp.txt
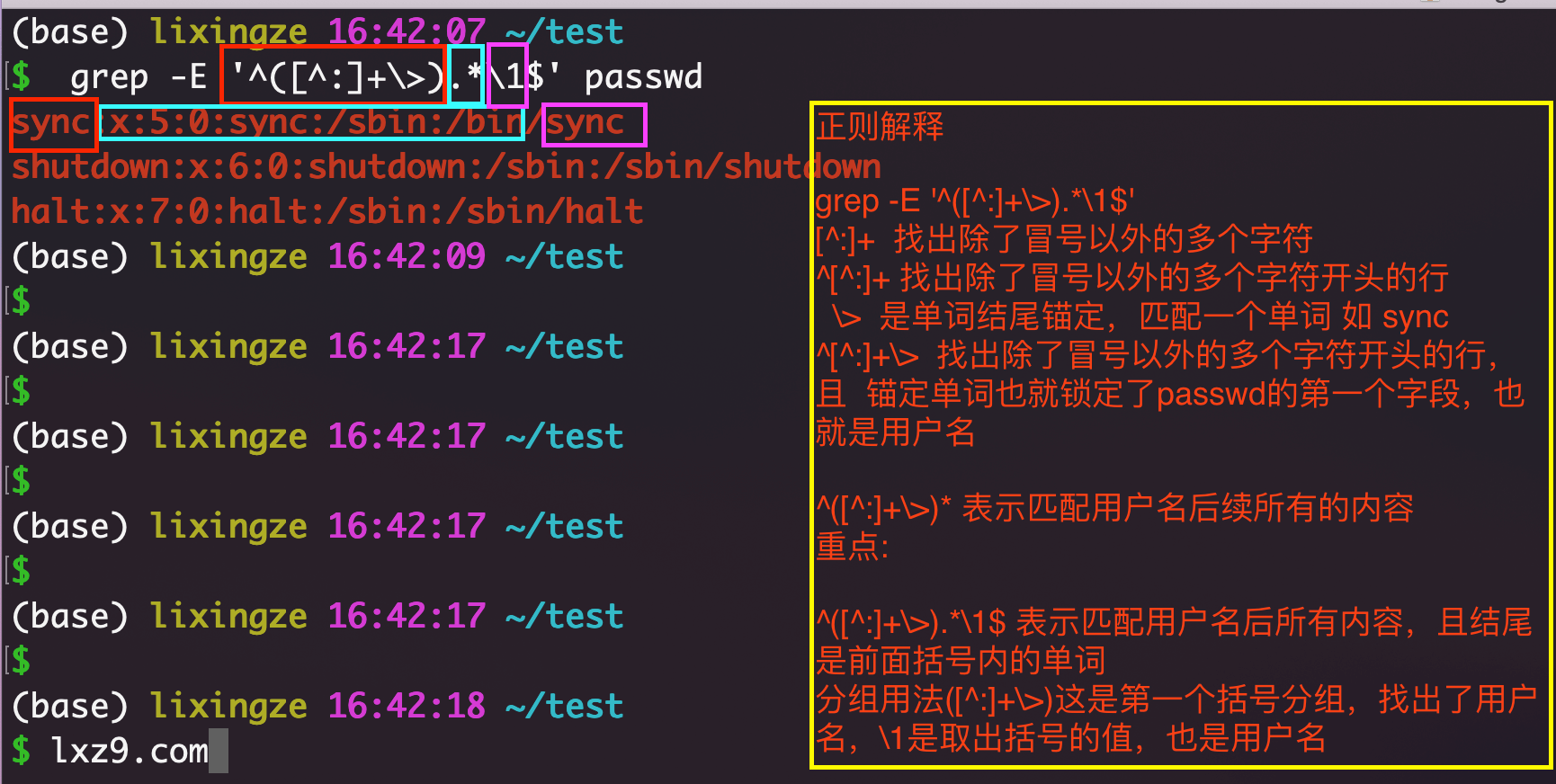
()小括号将一个或多个字符捆绑在一起,当作一个整体进行处理;
小括号功能之一是分组过滤被括起来的内容,括号内的内容表示一个整体后面的"\n"正则引用,n为数字,表示引用第几个括号的内容
\1:表示从左侧起,第一个括号中的模式所匹配到的字符\2:从左侧期,第二个括号中的模式所匹配到的字符
分组解释
分组案例:找出,用户名,shell名相同的行
sed
sed是Stream Editor(字符流编辑器)的缩写,简称流编辑器。
常用功能包括结合正则表达式对文件实现快速增删改查,其中查询的功能中最常用的两大功能是过滤(过滤指定字符串)、取行(取出指定行)。
语法
1 2 3 4 5 6 7 8 sed [选项] [sed内置命令字符] [输入文件] -n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行 -e:多点编辑,对每行处理时,可以有多个Script -f:把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写 -r:支持扩展的正则表达式 -i:直接将处理的结果写入文件 -i.bak:在将处理的结果写入文件之前备份一份
选项
参数选项
解释
-n
取消默认sed的输出,常与sed内置命令p一起用
-i
直接将修改结果写入文件,不用-i,sed修改的是内存数据
-e
多次编辑,不需要管道符了
-r
支持正则扩展
sed的内置命令字符用于对文件进行不同的操作功能,如对文件增删改查
sed常用内置命令字符
sed的内置命令字符
解释
a
append,对文本追加,在指定行后面添加一行/多行文本
d
Delete,删除匹配行
i
insert,表示插入文本,在指定行前添加一行/多行文本
p
Print ,打印匹配行的内容,通常p与-n一起用
s/正则/替换内容/g
匹配正则内容,然后替换内容(支持正则),结尾g代表全局匹配
sed匹配范围
范围
解释
空地址
全文处理
单地址
指定文件某一行
/pattern/
被模式匹配到的每一行
范围区间
10,20 十到二十行,10,+5第10行向下5行,/pattern1/,/pattern2/
步长
1~2,表示1、3、5、7、9行,2~2两个步长,表示2、4、6、8、10、偶数行
sed案例
准备测试数据
1 2 3 4 5 6 7 $ cat lxz I study linux. I want be better My website is https://lxz9.com My name is li This is a test file In order to learn Linux better
1 2 3 $ sed -n '2,3p' lxz I want be better My website is https://lxz9.com
1 2 $ sed -n '/lxz9.com/p' lxz My website is https://lxz9.com
注:sed想要修改文件内容,使用-i参数
1 2 3 4 5 6 7 8 $ sed '/linux/d' lxz I want be better My website is https://lxz9.com My name is li This is a test file In order to learn Linux better #含有linux的第一行被删除掉了
修改结果写入到文件
1 $ sed -i '/linux/d' lxz #不会输出结果,直接写入文件
删掉2,3两行sed '2,3d' lxz
删除第5行到结尾sed '5,$d' lxz
s内置符配合g,代表全局替换,中间的"/“可以替换为”#@/"等
1 2 3 4 5 6 $ sed 's/My/Her/g' lxz I want be better Her website is https://lxz9.com Her name is li This is a test file In order to learn Linux better
替换所有My为Her,同时换掉lxz9为baidu
1 2 3 4 5 6 $ sed -e 's/My/Her/g' -e 's/lxz9/baidu/g' lxz I want be better Her website is https://baidu.com Her name is li This is a test file In order to learn Linux better
在文件第二行追加内容 a字符功能,写入到文件,还得添加 -i
1 2 3 4 5 6 7 8 9 $ sed -i '2a I am useing sed command' lxz $ cat lxz #在第二行下面添加了内容 I want be better My website is https://lxz9.com I am useing sed command My name is li This is a test file In order to learn Linux better
添加多行信息,用换行符\n
1 2 3 4 5 6 7 8 9 10 11 $ sed -i "2a abc.\nbcd." lxz $ cat -n lxz 1 I want be better 2 My website is https://lxz9.com 3 abc. 4 bcd. 5 I am useing sed command 6 My name is li 7 This is a test file 8 In order to learn Linux better
在每一行下面插入新内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 $ sed "a ---" lxz I want be better --- My website is https://lxz9.com --- abc. --- bcd. --- I am useing sed command --- My name is li --- This is a test file --- In order to learn Linux better ---
sed '2i I am useing sed command' lxz
sed配合正则表达式案例
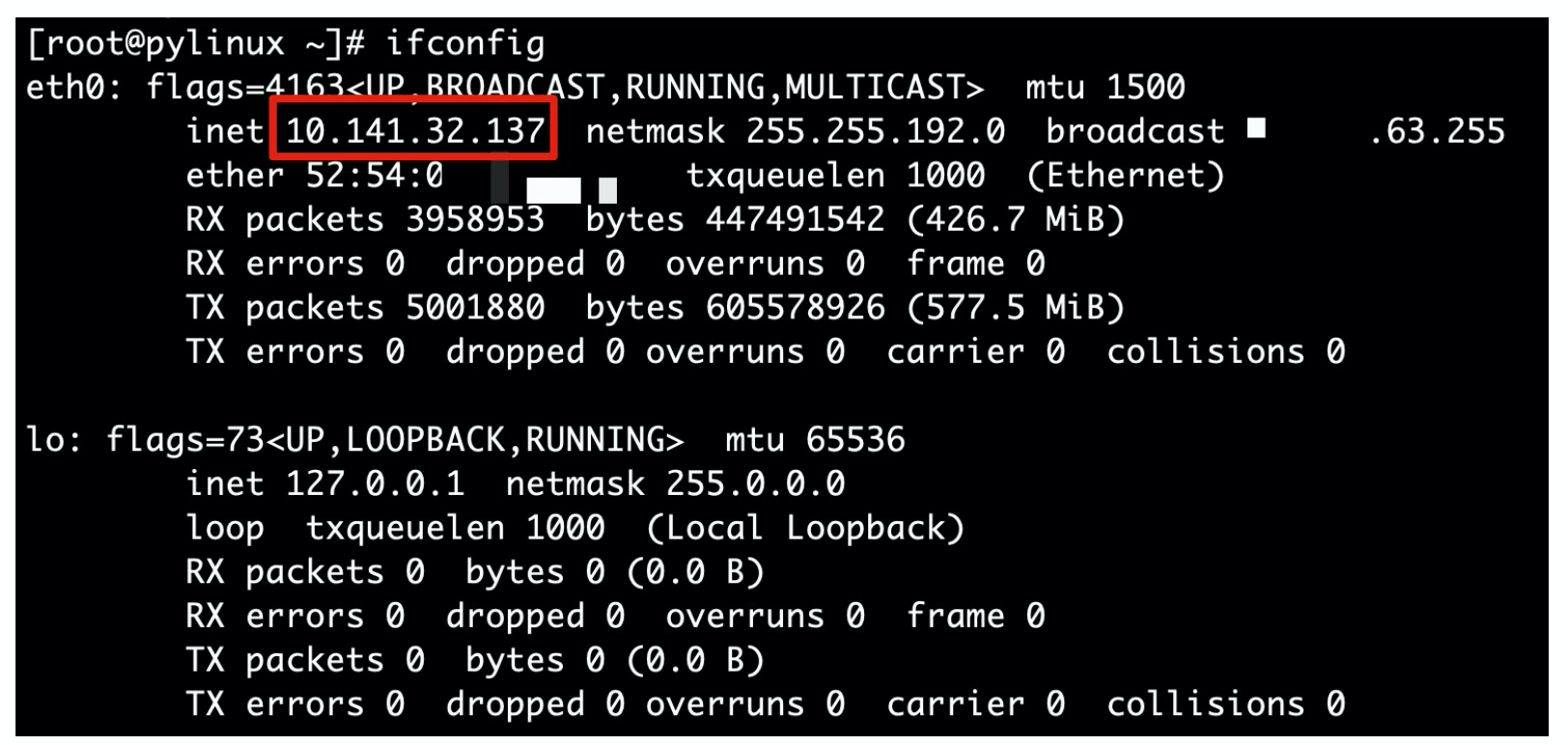
取出linux的IP地址
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1.首先取出第二行 # ifconfig | sed -n '2p' inet 10.141.32.137 netmask 255.255.192.0 broadcast 10.141.63.255 2.找到第二行后,去掉ip之前的内容 # ifconfig eth0|sed -n '2s#^.*inet##gp' 10.141.32.137 netmask 255.255.192.0 broadcast 10.141.63.255 解释: -n是取消默认输出 2s是处理第二行内容 #^.*inet## 是匹配inet前所有的内容 gp代表全局替换且打印替换结果 3.再次处理,去掉ip后面的内容 # sed -n '2s/^.*inet//gp' ip.txt | sed -n 's/net.*$//gp' 10.141.32.137 解释: net.*$ 匹配net到结尾的内容 s/net.*$//gp #把匹配到的内容替换为空
1 2 # ifconfig eth0 | sed -ne '2s/^.*inet//g' -e '2s/net.*$//gp' 10.141.32.137
awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk是一个强大的linux命令,有强大的文本格式化的能力,好比将一些文本数据格式化成专业的excel表的样式
语法
1 2 3 4 5 6 7 awk [option] 'pattern[action]' file ... awk [选项参数] 'script' var=value file(s) awk [选项参数] -f scriptfile var=value file(s)
awk使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #示例文件内容如下 cat awk_test lxz1 lxz11 lxz21 lxz31 lxz41 lxz2 lxz12 lxz22 lxz32 lxz42 lxz3 lxz13 lxz23 lxz33 lxz43 lxz4 lxz14 lxz24 lxz34 lxz44 lxz5 lxz15 lxz25 lxz35 lxz45 lxz6 lxz16 lxz26 lxz36 lxz46 lxz7 lxz17 lxz27 lxz37 lxz47 lxz8 lxz18 lxz28 lxz38 lxz48 lxz9 lxz19 lxz29 lxz39 lxz49 lxz10 lxz20 lxz30 lxz40 lxz50 cat awk_test | awk '{print $5}' lxz41 lxz42 lxz43 lxz44 lxz45 lxz46 lxz47 lxz48 lxz49 lxz50
执行的命令是awk '{print $5}',没有使用参数和模式,$5表示输出文本的第五列信息
$0表示整行 $NF表示当前分割后的最后一列 倒数第二列可以写成$(NF-1)
awk内置变量
内置变量
解释
$n
指定分隔符后,当前记录的第n个字段
$0
完整的输入记录
FS
字段分隔符,默认是空格
NF(Number of fields)
分割后,当前行一共有多少个字段
NR(Number of records)
当前记录数,行数
更多内置变量可以man手册查看
man awk
一次性输出多列
1 2 3 4 5 6 7 8 9 10 11 $ awk '{print $1,$2}' awk_test lxz1 lxz11 lxz2 lxz12 lxz3 lxz13 lxz4 lxz14 lxz5 lxz15 lxz6 lxz16 lxz7 lxz17 lxz8 lxz18 lxz9 lxz19 lxz10 lxz20
自动定义输出内容
awk,必须外层单引号,内层双引号$1、$2都不得添加双引号,否则会识别为文本,尽量别加引号
1 2 3 4 5 6 7 8 9 10 11 $ awk '{print "第一列",$1,"第二列",$2,"第五列",$5}' awk_test 第一列 lxz1 第二列 lxz11 第五列 lxz41 第一列 lxz2 第二列 lxz12 第五列 lxz42 第一列 lxz3 第二列 lxz13 第五列 lxz43 第一列 lxz4 第二列 lxz14 第五列 lxz44 第一列 lxz5 第二列 lxz15 第五列 lxz45 第一列 lxz6 第二列 lxz16 第五列 lxz46 第一列 lxz7 第二列 lxz17 第五列 lxz47 第一列 lxz8 第二列 lxz18 第五列 lxz48 第一列 lxz9 第二列 lxz19 第五列 lxz49 第一列 lxz10 第二列 lxz20 第五列 lxz50
输出整行信息
1 2 awk '{print}' awk_test awk '{print $0}' awk_test
awk选项参数说明
参数
解释
-F
指定分割字段符
-v
定义或修改一个awk内部的变量
-f
从脚本文件中读取awk命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 -F fs or --field-separator fs 指定分割字段符,fs是一个字符串或者是一个正则表达式,如-F:。 -v var=value or --asign var=value 定义或修改一个awk内部的变量 -f scripfile or --file scriptfile 从脚本文件中读取awk命令。 -mf nnn and -mr nnn 对nnn值设置内在限制,-mf选项限制分配给nnn的最大块数目;-mr选项限制记录的最大数目。这两个功能是Bell实验室版awk的扩展功能,在标准awk中不适用。 -W compact or --compat, -W traditional or --traditional 在兼容模式下运行awk。所以gawk的行为和标准的awk完全一样,所有的awk扩展都被忽略。 -W copyleft or --copyleft, -W copyright or --copyright 打印简短的版权信息。 -W help or --help , -W usage or --usage 打印全部awk选项和每个选项的简短说明。 -W lint or --lint 打印不能向传统unix平台移植的结构的警告。 -W lint-old or --lint-old 打印关于不能向传统unix平台移植的结构的警告。 -W posix 打开兼容模式。但有以下限制,不识别:/x、函数关键字、func、换码序列以及当fs是一个空格时,将新行作为一个域分隔符;操作符**和**=不能代替^和^=;fflush无效。 -W re-interval or --re-inerval 允许间隔正则表达式的使用,参考(grep中的Posix字符类),如括号表达式[[:alpha:]]。 -W source program-text or --source program-text 使用program-text作为源代码,可与-f命令混用。 -W version or --version 打印bug报告信息的版本。
显示文件第三行
1 2 3 4 5 #NR在awk中表示行号,NR==3表示行号是3的那一行 #注意一个等于号,是修改变量值的意思,两个等于号是关系运算符,是"等于"的意思 $ awk 'NR==3' awk_test lxz3 lxz13 lxz23 lxz33 lxz43
显示文件2-5行
1 2 3 4 5 $ awk 'NR==2,NR==5' awk_test lxz2 lxz12 lxz22 lxz32 lxz42 lxz3 lxz13 lxz23 lxz33 lxz43 lxz4 lxz14 lxz24 lxz34 lxz44 lxz5 lxz15 lxz25 lxz35 lxz45
给每一行的内容添加行号
添加变量,NR等于行号,$0表示一整行的内容
{print }是awk的动作
1 2 3 4 5 6 7 8 9 10 11 $ awk '{print NR,$0}' awk_test 1 lxz1 lxz11 lxz21 lxz31 lxz41 2 lxz2 lxz12 lxz22 lxz32 lxz42 3 lxz3 lxz13 lxz23 lxz33 lxz43 4 lxz4 lxz14 lxz24 lxz34 lxz44 5 lxz5 lxz15 lxz25 lxz35 lxz45 6 lxz6 lxz16 lxz26 lxz36 lxz46 7 lxz7 lxz17 lxz27 lxz37 lxz47 8 lxz8 lxz18 lxz28 lxz38 lxz48 9 lxz9 lxz19 lxz29 lxz39 lxz49 10 lxz10 lxz20 lxz30 lxz40 lxz50
显示文件3-5行且输出行号
1 2 3 4 $ awk 'NR==3,NR==5 {print NR,$0}' awk_test 3 lxz3 lxz13 lxz23 lxz33 lxz43 4 lxz4 lxz14 lxz24 lxz34 lxz44 5 lxz5 lxz15 lxz25 lxz35 lxz45
显示文件的第一列,倒数第二和最后一列
1 awk -F ' ' '{print $1,$(NF-1),$NF}' pwd.txt
awk分隔符
awk的分隔符有两种
输入分隔符,awk默认是空格,空白字符,英文是field separator,变量名是FS
输出分隔符,output field separator,简称OFS
FS输入分隔符
awk逐行处理文本的时候,以输入分割符为准,把文本切成多个片段,默认符号是空格
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $ cat awk_test lxz1,lxz11,lxz21,lxz31,lxz41 lxz2,lxz12,lxz22,lxz32,lxz42 lxz3,lxz13,lxz23,lxz33,lxz43 lxz4,lxz14,lxz24,lxz34,lxz44 lxz5,lxz15,lxz25,lxz35,lxz45 lxz6,lxz16,lxz26,lxz36,lxz46 lxz7,lxz17,lxz27,lxz37,lxz47 lxz8,lxz18,lxz28,lxz38,lxz48 lxz9,lxz19,lxz29,lxz39,lxz49 lxz10,lxz20,lxz30,lxz40,lxz50 $ awk -F ',' '{print $1}' awk_test lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10
除了使用-F选项,还可以使用变量的形式,指定分隔符,使用-v选项搭配,修改FS变量
1 2 3 4 5 6 7 8 9 10 11 $ awk -v FS=',' '{print $1}' awk_test lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10
OFS输出分割符
awk执行完命令,默认用空格隔开每一列,这个空格就是awk的默认输出符,例如
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 $ cat awk_test lxz1,lxz11,lxz21,lxz31,lxz41 lxz2,lxz12,lxz22,lxz32,lxz42 lxz3,lxz13,lxz23,lxz33,lxz43 lxz4,lxz14,lxz24,lxz34,lxz44 lxz5,lxz15,lxz25,lxz35,lxz45 lxz6,lxz16,lxz26,lxz36,lxz46 lxz7,lxz17,lxz27,lxz37,lxz47 lxz8,lxz18,lxz28,lxz38,lxz48 lxz9,lxz19,lxz29,lxz39,lxz49 lxz10,lxz20,lxz30,lxz40,lxz50 $ awk -v FS=',' '{print $1,$3}' awk_test lxz1 lxz21 lxz2 lxz22 lxz3 lxz23 lxz4 lxz24 lxz5 lxz25 lxz6 lxz26 lxz7 lxz27 lxz8 lxz28 lxz9 lxz29 lxz10 lxz30 通过OFS设置输出分割符,修改变量必须搭配选项 -v $ awk -v FS=',' -v OFS='-~-' '{print $1,$3 }' awk_test lxz1-~-lxz21 lxz2-~-lxz22 lxz3-~-lxz23 lxz4-~-lxz24 lxz5-~-lxz25 lxz6-~-lxz26 lxz7-~-lxz27 lxz8-~-lxz28 lxz9-~-lxz29 lxz10-~-lxz30
输出分隔符与逗号
awk是否存在输出分隔符,特点在于'{print $1,$3 }逗号的区别
1 2 3 4 5 6 7 8 9 10 11 $ awk -v FS=',' '{print $1,$3}' awk_test lxz1 lxz21 lxz2 lxz22 lxz3 lxz23 lxz4 lxz24 lxz5 lxz25 lxz6 lxz26 lxz7 lxz27 lxz8 lxz28 lxz9 lxz29 lxz10 lxz30
1 2 3 4 5 6 7 8 9 10 11 $ awk -v FS=',' '{print $1$3}' awk_test lxz1lxz21 lxz2lxz22 lxz3lxz23 lxz4lxz24 lxz5lxz25 lxz6lxz26 lxz7lxz27 lxz8lxz28 lxz9lxz29 lxz10lxz30
修改分割符,改为\t(制表符,四个空格)或者任意字符
1 2 3 4 5 6 7 8 9 10 11 awk -v FS=',' -v OFS='\t' '{print $1,$3 }' awk_test lxz1 lxz21 lxz2 lxz22 lxz3 lxz23 lxz4 lxz24 lxz5 lxz25 lxz6 lxz26 lxz7 lxz27 lxz8 lxz28 lxz9 lxz29 lxz10 lxz30
awk变量
内置变量
解释
FS
输入字段分隔符, 默认为空白字符
OFS
输出字段分隔符, 默认为空白字符
RS
输入记录分隔符(输入换行符), 指定输入时的换行符
ORS
输出记录分隔符(输出换行符),输出时用指定符号代替换行符
NF
NF:number of Field,当前行的字段的个数(即当前行被分割成了几列),字段数量
NR
NR:行号,当前处理的文本行的行号。
FNR
FNR:各文件分别计数的行号
FILENAME
FILENAME:当前文件名
ARGC
ARGC:命令行参数的个数
ARGV
ARGV:数组,保存的是命令行所给定的各参数
内置变量
NR,NF、FNR
awk的内置变量NR、NF是不用添加$符号的3... 是需要添加 3 ... 是需要添加 3... 是需要添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # sed将逗号替换为空格 $ sed -i 's/,/ /g' awk_test $ cat awk_test lxz1 lxz11 lxz21 lxz31 lxz41 lxz2 lxz12 lxz22 lxz32 lxz42 lxz3 lxz13 lxz23 lxz33 lxz43 lxz4 lxz14 lxz24 lxz34 lxz44 lxz5 lxz15 lxz25 lxz35 lxz45 lxz6 lxz16 lxz26 lxz36 lxz46 lxz7 lxz17 lxz27 lxz37 lxz47 lxz8 lxz18 lxz28 lxz38 lxz48 lxz9 lxz19 lxz29 lxz39 lxz49 lxz10 lxz20 lxz30 lxz40 lxz50 $ awk '{print NR,NF}' awk_test 1 5 2 5 3 5 4 5 5 5 6 5 7 5 8 5 9 5 10 5
输出每行行号,以及指定的列
1 2 3 4 5 6 7 8 9 10 11 $ awk '{print NR,$1,$5}' awk_test 1 lxz1 lxz41 2 lxz2 lxz42 3 lxz3 lxz43 4 lxz4 lxz44 5 lxz5 lxz45 6 lxz6 lxz46 7 lxz7 lxz47 8 lxz8 lxz48 9 lxz9 lxz49 10 lxz10 lxz50
处理多个文件显示行号
1 2 3 4 # 普通的NR变量,会将多个文件按照顺序排序 awk '{print NR,$0}' a.txt b.txt # 使用FNR变量,可以分别对文件行数计数 awk '{print FNR,$0}' a.txt b.txt
内置变量ORS
ORS是输出分隔符的意思,awk默认认为,每一行结束了,就得添加回车换行符
1 2 $ awk -v ORS=';;;' '{print NR,$0}' awk_test 1 lxz1 lxz11 lxz21 lxz31 lxz41;;;2 lxz2 lxz12 lxz22 lxz32 lxz42;;;3 lxz3 lxz13 lxz23 lxz33 lxz43;;;4 lxz4 lxz14 lxz24 lxz34 lxz44;;;5 lxz5 lxz15 lxz25 lxz35 lxz45;;;6 lxz6 lxz16 lxz26 lxz36 lxz46;;;7 lxz7 lxz17 lxz27 lxz37 lxz47;;;8 lxz8 lxz18 lxz28 lxz38 lxz48;;;9 lxz9 lxz19 lxz29 lxz39 lxz49;;;10 lxz10 lxz20 lxz30 lxz40 lxz50;;;
内置变量FILENAME
显示awk正在处理文件的名字
1 2 3 4 5 6 7 8 9 10 11 12 13 $ awk '{print FILENAME,FNR,$0}' awk_test test1 test2 awk_test 1 lxz1 lxz11 lxz21 lxz31 lxz41 awk_test 2 lxz2 lxz12 lxz22 lxz32 lxz42 awk_test 3 lxz3 lxz13 lxz23 lxz33 lxz43 awk_test 4 lxz4 lxz14 lxz24 lxz34 lxz44 awk_test 5 lxz5 lxz15 lxz25 lxz35 lxz45 awk_test 6 lxz6 lxz16 lxz26 lxz36 lxz46 awk_test 7 lxz7 lxz17 lxz27 lxz37 lxz47 awk_test 8 lxz8 lxz18 lxz28 lxz38 lxz48 awk_test 9 lxz9 lxz19 lxz29 lxz39 lxz49 awk_test 10 lxz10 lxz20 lxz30 lxz40 lxz50 test1 1 文件一 test2 1 文件二
变量ARGC、ARGV
ARGV表示的是一个数组,数组中保存的是命令行所给的参数
自定义变量
方法一: -v varName=value
1 2 $ awk -v lxz9com="我的网址lxz9.com" 'BEGIN{print lxz9com}' 我的网址lxz9.com
方法二:在程序中直接定义
1 2 $ awk 'BEGIN{abc="字母abc";def="字母def";print abc,def}' 字母abc 字母def
awk格式化
printf和print的区别
format的使用
要点:
format格式的指示符都以%开头,后跟一个字符;如下:
printf修饰符:
printf动作默认不会添加换行符 print默认添加空格换行符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ awk '{print $1}' awk_test lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10 $ awk '{printf $1}' awk_test lxz1lxz2lxz3lxz4lxz5lxz6lxz7lxz8lxz9lxz10
给printf添加格式
格式化字符串 %s 代表字符串的意思 \n 换行符
1 2 3 4 5 6 7 8 9 10 11 $ awk '{printf "%s\n",$1}' awk_test lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10
对多个变量进行格式化
使用linux命令printf时,是这样的,一个%s格式替换符,可以对多个参数进行重复格式化
1 2 3 4 5 $ printf "%s\n" a b c d a b c d
1 2 3 4 5 6 7 8 $ awk 'BEGIN{printf "%d\n%d\n%d\n%d\n%d\n",1,2,3,4,5}' 1 2 3 4 5 # %D 代表是十进制数字
printf对输出的文本不会换行,必须添加对应的格式替换符和\n
使用printf动作,'{printf "%s\n",$1}',替换的格式和变量之间得有逗号,
使用printf动作,%s %d 等格式化替换符 必须 和被格式化的数据一一对应
awk模式
1 awk [option] 'pattern[action]' file
awk是按行处理文本
BEGIN模式是处理文本之前需要执行的操作
END模式是处理完所有行之后执行的操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 $ awk 'BEGIN{print "lxz9.com"}{print $1}' awk_test lxz9.com lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10 $ awk 'END{print "lxz9.com"}{print $1}' awk_test $ awk 'END{print "lxz9.com"}{print $1}' awk_test lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10 lxz9.com
关系运算符
解释
示例
<小于
x<y
<=小于等于
x<=y
==等于
x==y
!=不等于
x!=y
>=大于等于
x>=y
>大于
x>y
~匹配正则
x~/正则/
!~不匹配正则
x!~/正则/
awk总结
空模式
没有指定任何的模式(条件),因此每一行都执行了对应的动作,空模式会匹配文档的每一行,每一行都满足了(空模式)
1 2 3 4 5 6 7 8 9 10 11 $ awk '{print $1}' awk_test lxz1 lxz2 lxz3 lxz4 lxz5 lxz6 lxz7 lxz8 lxz9 lxz10
关系运算符模式
awk默认执行打印输出动作
1 2 3 4 5 $ awk 'NR==2,NR==5' awk_test lxz2 lxz12 lxz22 lxz32 lxz42 lxz3 lxz13 lxz23 lxz33 lxz43 lxz4 lxz14 lxz24 lxz34 lxz44 lxz5 lxz15 lxz25 lxz35 lxz45
BEGIN/END模式(条件设置)
1 2 3 4 5 6 7 8 9 10 11 12 13 $ awk 'BEGIN{print "我在开头位置"}{print $1,$2}END{print "我在结尾处"}' awk_test 我在开头位置 lxz1 lxz11 lxz2 lxz12 lxz3 lxz13 lxz4 lxz14 lxz5 lxz15 lxz6 lxz16 lxz7 lxz17 lxz8 lxz18 lxz9 lxz19 lxz10 lxz20 我在结尾处
awk与正则表达式
正则表达式主要与awk的pattern模式(条件)结合使用
不指定模式,awk每一行都会执行对应的动作
找出a文件中有以export开头的行
用grep过滤
1 2 3 4 $ grep '^export' a export PATH="/home/lixingze/software/samtools-1.11/bin:$PATH" export PATH="/home/lixingze/software/species-0.3.1$PATH" export PATH="/home/lixingze/software/matplotlib-3.3.2:$PATH"
awk
1 2 3 4 5 6 7 8 9 10 $ awk '/^export/{print $0}' a export PATH="/home/lixingze/software/samtools-1.11/bin:$PATH" export PATH="/home/lixingze/software/species-0.3.1$PATH" export PATH="/home/lixingze/software/matplotlib-3.3.2:$PATH" #省略写法 $ awk '/^export/' a export PATH="/home/lixingze/software/samtools-1.11/bin:$PATH" export PATH="/home/lixingze/software/species-0.3.1$PATH" export PATH="/home/lixingze/software/matplotlib-3.3.2:$PATH"
awk使用正则语法
grep ‘正则表达式’ a.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 $ cat -n passwd 1 root❌ 0:0:root:/root:/bin/bash 2 bin❌ 1:1:bin:/bin:/sbin/nologin 3 daemon❌ 2:2:daemon:/sbin:/sbin/nologin 4 adm❌ 3:4:adm:/var/adm:/sbin/nologin 5 lp❌ 4:7:lp:/var/spool/lpd:/sbin/nologin 6 sync❌ 5:0:sync:/sbin:/bin/sync 7 shutdown❌ 6:0:shutdown:/sbin:/sbin/shutdown 8 halt❌ 7:0:halt:/sbin:/sbin/halt 9 mail❌ 8:12:mail:/var/spool/mail:/sbin/nologin 10 operator❌ 11:0:operator:/root:/sbin/nologin 11 games❌ 12💯 games:/usr/games:/sbin/nologin 12 ftp❌ 14:50:FTP User:/var/ftp:/sbin/nologin 13 nobody❌ 65534:65534:Kernel Overflow User:/:/sbin/nologin 14 dbus❌ 81:81:System message bus:/:/sbin/nologin 15 systemd-coredump❌ 999:997:systemd Core Dumper:/:/sbin/nologin 16 systemd-resolve❌ 193:193:systemd Resolver:/:/sbin/nologin 17 tss❌ 59:59:Account used by the trousers package to sandbox the tcsd daemon:/dev/null:/sbin/nologin 18 polkitd❌ 998:996:User for polkitd:/:/sbin/nologin 19 grafana❌ 997:995:grafana user account:/usr/share/grafana:/sbin/nologin 20 unbound❌ 996:993:Unbound DNS resolver:/etc/unbound:/sbin/nologin 21 gluster❌ 995:992:GlusterFS daemons:/run/gluster:/sbin/nologin 22 geoclue❌ 994:991:User for geoclue:/var/lib/geoclue:/sbin/nologin 23 rtkit❌ 172:172:RealtimeKit:/proc:/sbin/nologin 24 pipewire❌ 993:990:PipeWire System Daemon:/var/run/pipewire:/sbin/nologin 25 pulse❌ 171:171:PulseAudio System Daemon:/var/run/pulse:/sbin/nologin 26 qemu❌ 107:107:qemu user:/:/sbin/nologin 27 apache❌ 48:48:Apache:/usr/share/httpd:/sbin/nologin 28 cockpit-ws❌ 992:986:User for cockpit-ws:/nonexisting:/sbin/nologin 29 usbmuxd❌ 113:113:usbmuxd user:/:/sbin/nologin 30 rpc❌ 32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin 31 saslauth❌ 988:76:Saslauthd user:/run/saslauthd:/sbin/nologin 32 sssd❌ 976:976:User for sssd:/:/sbin/nologin 33 pcp❌ 991:985:Performance Co-Pilot:/var/lib/pcp:/sbin/nologin 34 chrony❌ 990:984::/var/lib/chrony:/sbin/nologin 35 libstoragemgmt❌ 989:982:daemon account for libstoragemgmt:/var/run/lsm:/sbin/nologin $ awk -F ":" 'BEGIN{printf "%-10s\t%-10s\n","用户名","用户id"} /^d/ {printf "%-10s\t%-10s\n",$1,$3}' passwd 用户名 用户id daemon 2 dbus 81
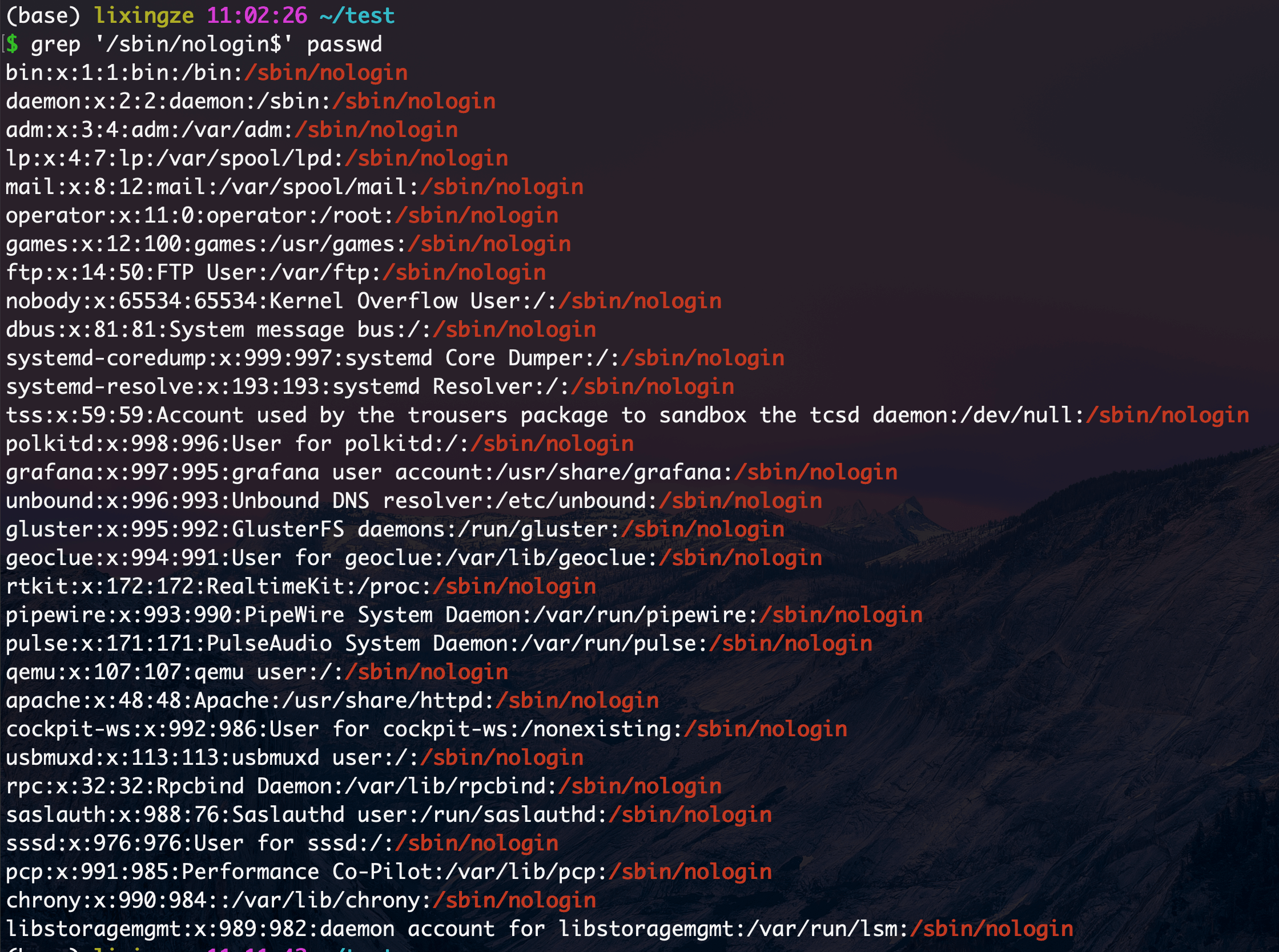
找出passwd文件中禁止登录的用户(/sbin/nologin)
正则表达式中如果出现了 "/"则需要进行转义
找出pwd.txt文件中禁止登录的用户(/sbin/nologin)
用grep找出
1 grep '/sbin/nologin$' passwd
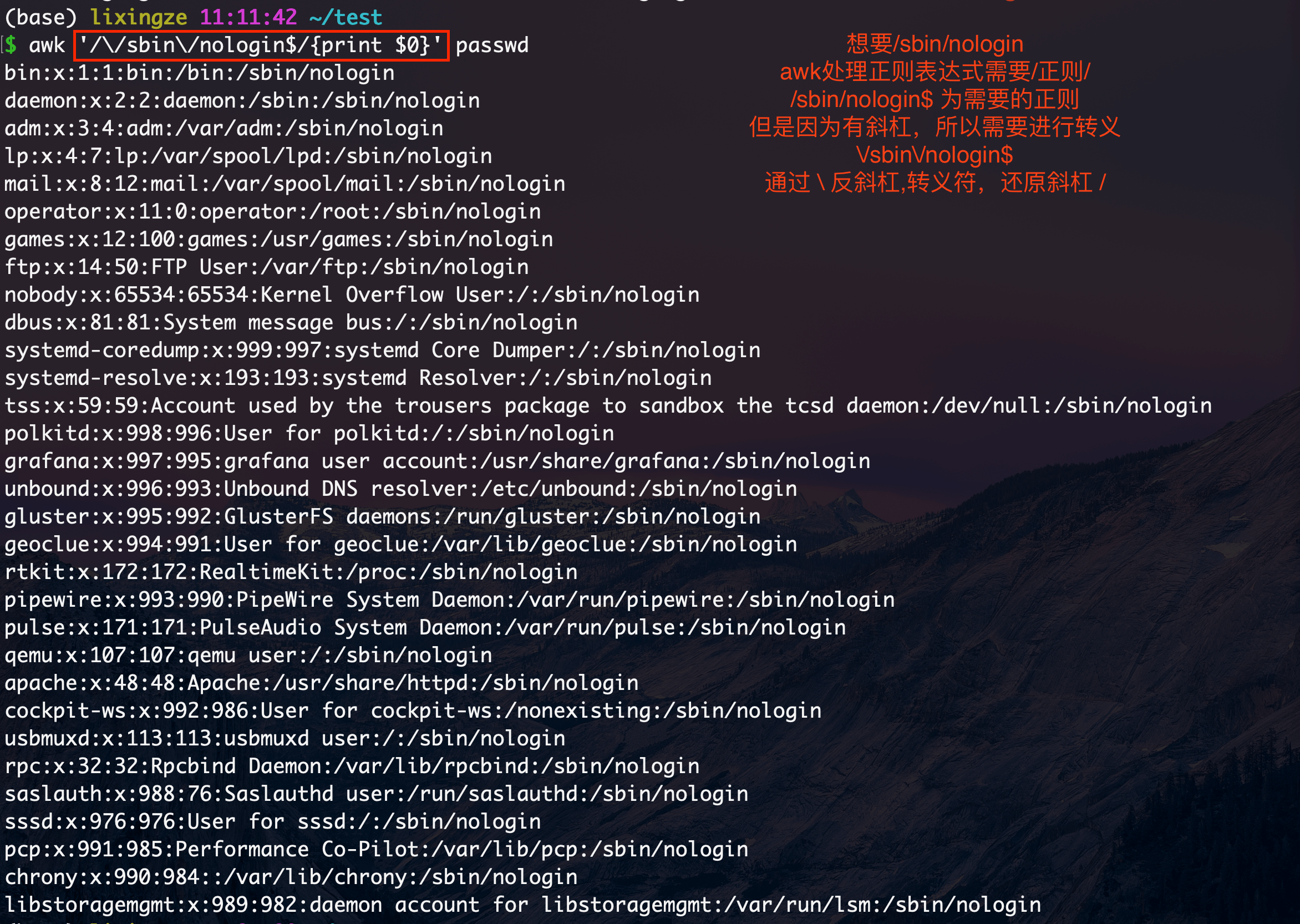
awk用正则得用双斜杠/正则表达式/
1 awk '/\/sbin\/nologin$/{print $0}' passwd
找出文件的区间内容
找出adm用户到mail用户之间的内容
正则模式awk '/正则表达式/{动作}' file
行范围模式awk '/正则1/,/正则2/{动作}' file
1 2 3 4 5 6 7 $ awk '/^adm/,/^mail/ {print $0}' passwd adm❌ 3:4:adm:/var/adm:/sbin/nologin lp❌ 4:7:lp:/var/spool/lpd:/sbin/nologin sync❌ 5:0:sync:/sbin:/bin/sync shutdown❌ 6:0:shutdown:/sbin:/sbin/shutdown halt❌ 7:0:halt:/sbin:/sbin/halt mail❌ 8:12:mail:/var/spool/mail:/sbin/nologin
关系表达式模式
1 2 3 4 5 6 7 $ awk 'NR>=4 && NR<=9 {print $0}' passwd adm❌ 3:4:adm:/var/adm:/sbin/nologin lp❌ 4:7:lp:/var/spool/lpd:/sbin/nologin sync❌ 5:0:sync:/sbin:/bin/sync shutdown❌ 6:0:shutdown:/sbin:/sbin/shutdown halt❌ 7:0:halt:/sbin:/sbin/halt mail❌ 8:12:mail:/var/spool/mail:/sbin/nologin
推荐
推荐学习相关计算机网课 路飞学城


 微信
微信 支付宝
支付宝










