data = pd.read_csv(sys.argv[1], sep="\t", header=None)
new = data[1].str.split('.').str data['id'] = new[0].values data['cha'] = data[3]-data[2]
for name, group in data.groupby(['id']): iflen(group) == 1: continue ind = group.sort_values(by='cha', ascending=False).index[1:].values data.drop(index=ind, inplace=True)
# data[2] =data[2].astype(int) # data[3] =data[3].astype(int) # for name, group in data.groupby(0): # if len(group) == 1: # continue # start=0 # # print(group.head()) # group = group.sort_values(by=[2,3],ascending=[True,False]) # for index, row in group.iterrows(): # # print(row) # if row[3]>start or row[2]>start: # start=max([row[3],row[2]]) # continue # data.drop(index=index, inplace=True) # ind = group.sort_values(by='cha', ascending=False).index[1:].values #print(name) # print(group.sort_values(by='cha',ascending=False))
# data = data[data[1].str.contains('\.mRNA1$')] data['order'] = '' data['newname'] = '' print(data.head()) for name, group in data.groupby([0]): number = len(group) group = group.sort_values(by=[2]) data.loc[group.index, 'order'] = list(range(1, len(group)+1)) data.loc[group.index, 'newname'] = list( ['ath2s'+str(name)+'g'+str(i).zfill(5) for i inrange(1, len(group)+1)]) data['order'] = data['order'].astype('int') data = data[[0, 'newname', 2, 3, 4, 'order', 1]] print(data.head()) data = data.sort_values(by=[0, 'order']) data.to_csv(sys.argv[2], sep="\t", index=False, header=None) lens = data.groupby(0).max()[[3, 'order']] lens.to_csv(sys.argv[3], sep="\t", header=None)
seq_newname.py
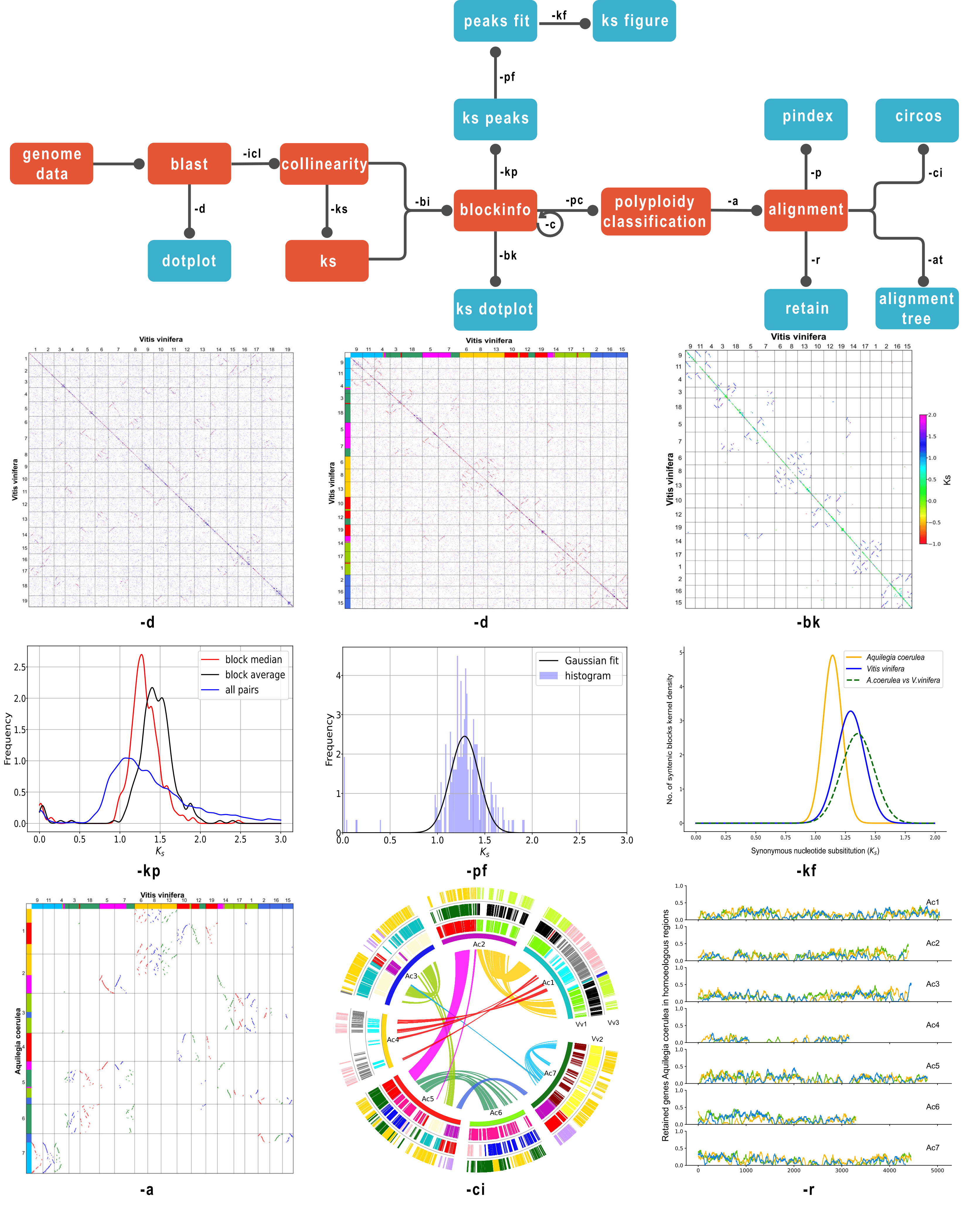
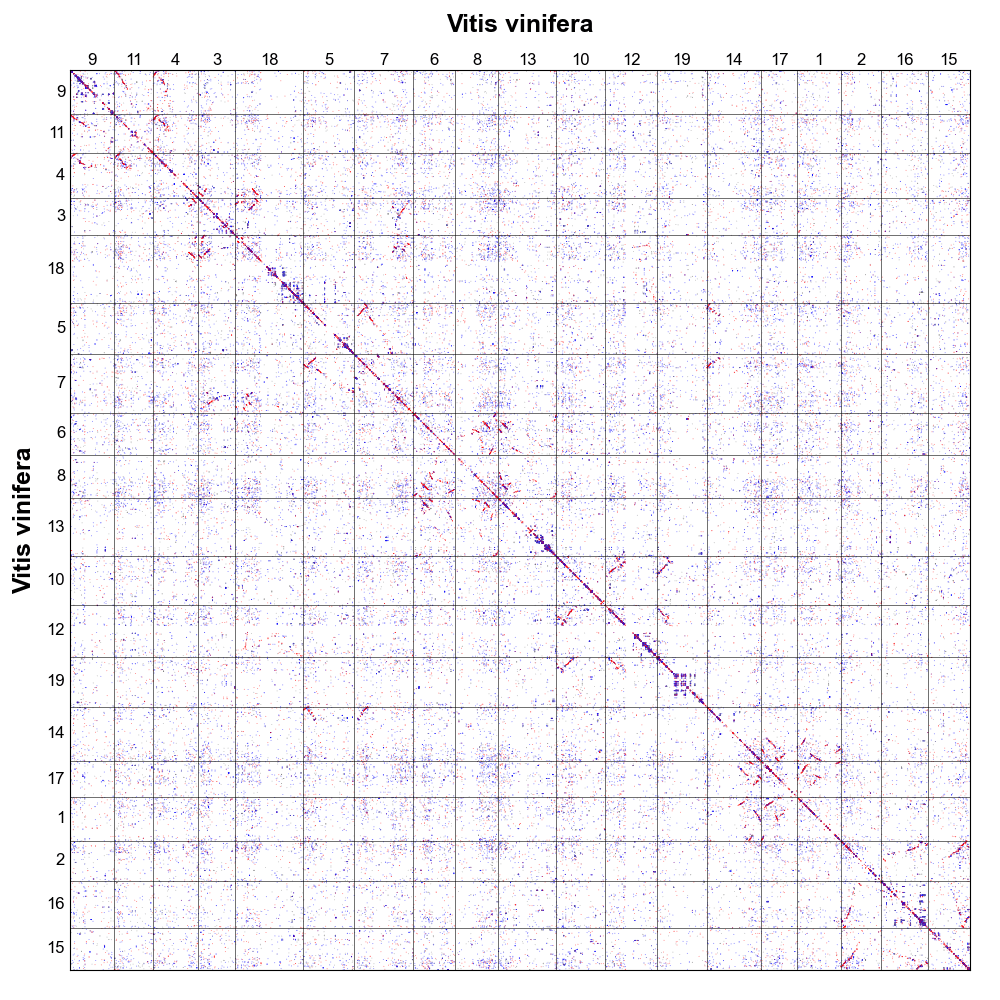
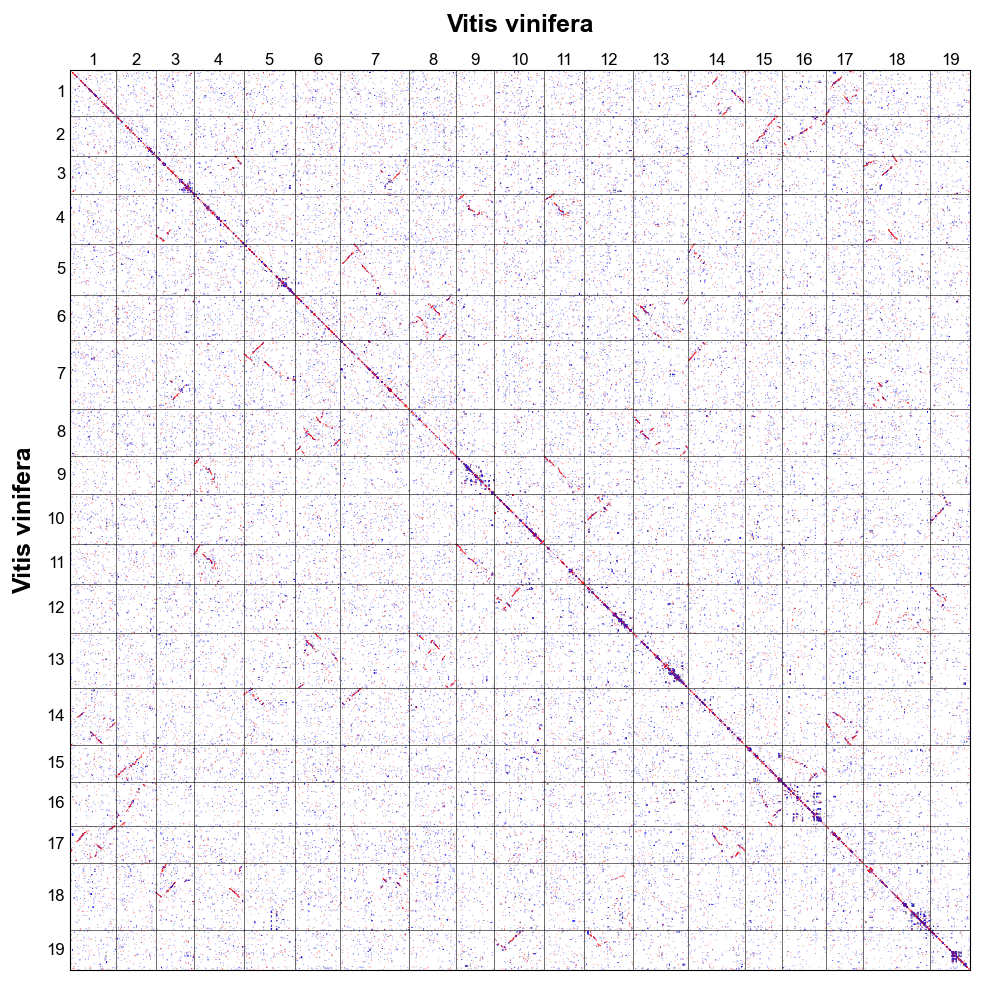
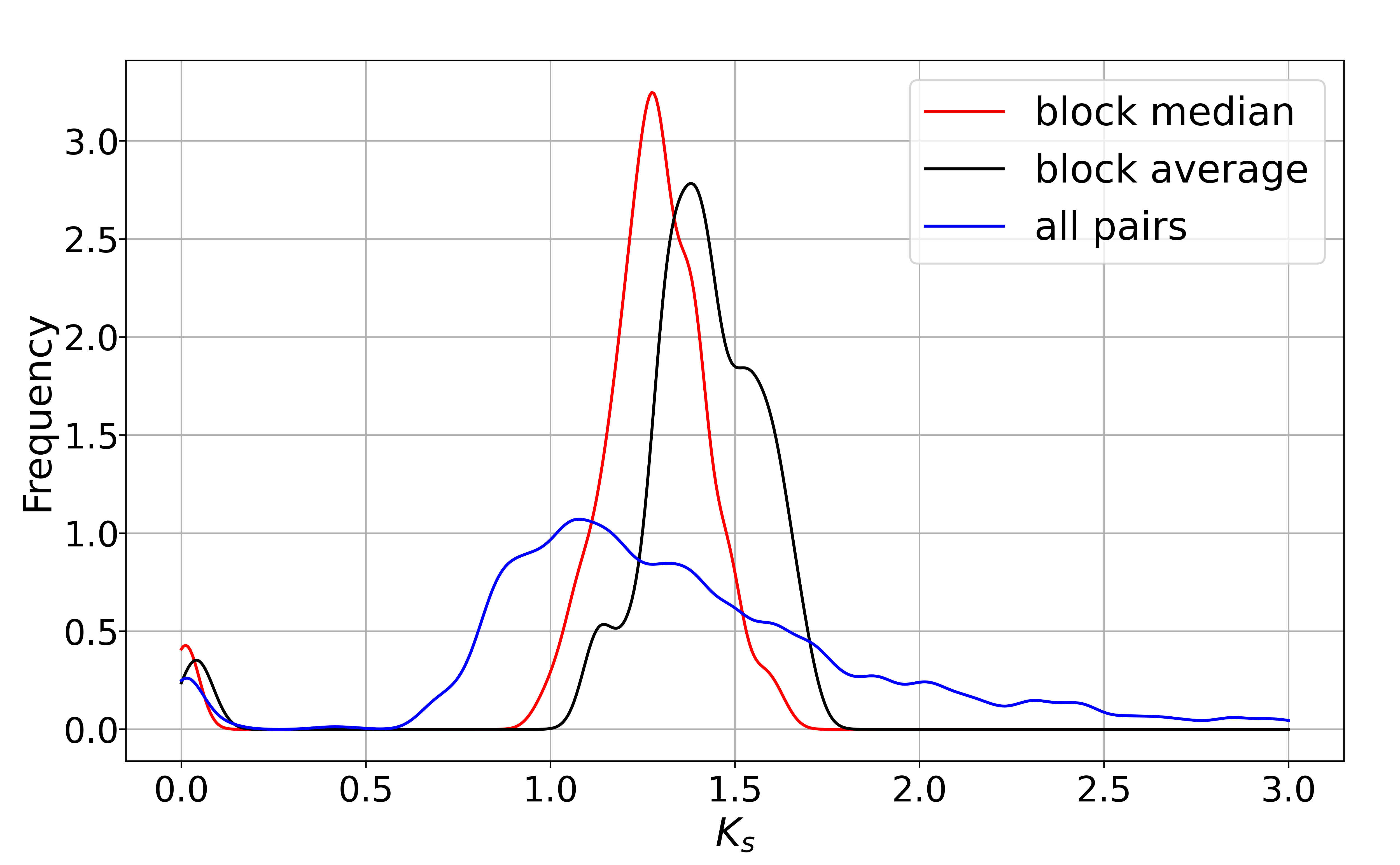
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import sys import pandas as pd from Bio import SeqIO
data = pd.read_csv(sys.argv[1], sep="\t", header=None, index_col=6) data.index = data.index.str[:-3] id_dict = data[1].to_dict() print(data.head()) seqs = [] n = 0 for seq_record in SeqIO.parse(sys.argv[2], "fasta"): if seq_record.idin id_dict: seq_record.id = id_dict[seq_record.id] n += 1 else: continue seqs.append(seq_record) SeqIO.write(seqs, sys.argv[3], "fasta") print(n)
# get the fasta len defget_fasta_len(fasta): fasta_dict = OrderedDict() handle = open(fasta, "r") active_sequence_name = "" for line in handle: line = line.strip() ifnot line: continue if line.startswith(">"): active_sequence_name = line[1:] active_sequence_name = active_sequence_name.split(" ")[0] if active_sequence_name notin fasta_dict: fasta_dict[active_sequence_name] = 0 continue sequence = line fasta_dict[active_sequence_name] += len(sequence) handle.close() return fasta_dict
for line in handle: if line.startswith("#"): continue content = line.split("\t") iflen(content) <= 8: continue #print(content) if content[2] == "transcript"or content[2] == "mRNA":
# use regual expression to extract the gene ID # match the pattern ID=xxxxx; or ID=xxxxx
tx_id = re.search(r'ID=(.*?)[;\n]',content[8]).group(1) tx_parent = re.search(r'Parent=(.*?)[;\n]',content[8]).group(1) tx_parent = tx_parent.strip() # remove the 'r' and '\n'
# if the parent of transcript is not in the gene_dict, create it rather than append if tx_parent in gene_dict: gene_dict[tx_parent].append(tx_id) else: gene_dict[tx_parent] = [tx_id] tx_pos_dict[tx_id] = [content[0],content[3], content[4], content[6] ] # GFF must have CDS feature if content[2] == 'CDS': width = int(content[4]) - int(content[3]) CDS_parent = re.search(r'Parent=(.*?)[;\n]',content[8]).group(1) CDS_parent = CDS_parent.strip() # strip the '\r' and '\n' CDS_dict[CDS_parent].append(width) handle.close() return [gene_dict, tx_pos_dict, CDS_dict]
for chrom,lens in fa_dict.items(): print("{chrom}\t{lens}\t{count}".format(\ chrom=chrom,lens=lens,count=gene_count[chrom]), file=len_file) len_file.close() gff_file.close()
参考文献
Sun P, Jiao B, Yang Y, et al. WGDI: A user-friendly toolkit for evolutionary analyses of whole-genome duplications and ancestral karyotypes[J]. bioRxiv, 2021.

 微信
微信 支付宝
支付宝










